This project describes
a smart, interactive children's bedtime story machine designed using Espressif Systems' ESP32MCU as the main controller.
It is licensed under
GPL 3.0.
Project features
include online voice storytelling, reciting poems and jokes, and music playback
. It supports voice interaction, allowing users to search for and read answers from the internet.
It supports TF card storage for offline use,
sleep reminders, and alarm clock reminders.
It supports charging and discharging, with a minimum usage time of 7 hours on a single charge. This
project
is being publicly disclosed for the first time and is an original work by the author. It has not won any awards in other competitions. The
project progress
involved designing the overall framework and planning the schedule upon receiving the project. On August 14, 2023,
the code was first verified on a development board. Completed writing the voice wake-up and voice detection code on the device side (August 21, 2023).
Completed debugging of Baidu Wenxin Yiyan and the voice recognition API (August 30, 2023).
Added offline mode, enabling offline playback of memory card resources (September 5, 2023).
Added sleep reminder and alarm clock functions to the device side, and designed an app for setting sleep reminders and alarm clocks (September 11, 2023).
Completed PCB design and prototyping (September 20, 2023).
PCB Testing 2023/9/29
Design the casing and prepare to write documentation 2023/10/7
Complete final device debugging and documentation writing 2023/10/17
Issue modification and improvement 2023/11/28
Project Introduction
The development of this project is mainly divided into three parts:
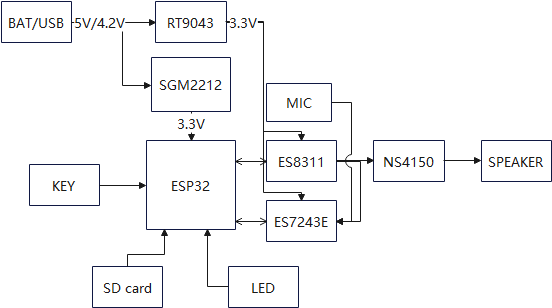
Device side: Uses ESP32 as the main control chip, and builds peripheral circuits around it to realize functions such as command word wake-up, voice activity detection, speech synthesis, and playback of audio from memory cards.
Cloud side: Mainly provides API interfaces for the online functions of the device side, such as Baidu Wenxin Yiyan API, Baidu Speech Recognition API (paid) and NetEase Cloud Music API service
Mobile APP side: Design a simple APP to realize device Smartconfig network configuration, device time synchronization, alarm clock, sleep reminder settings, etc.
Development tools
This project is divided into three parts:
1. Device side: Uses ESP-IDF and ESP-ADF for ESP32 device side development
2. Cloud side: Requires the use of Baidu Wenxin Yiyan API and Baidu Speech Recognition API (paid) to realize voice interaction, and needs to build NetEase Cloud Music API on local computer or cloud server. 3. Mobile
App: Develop the mobile app using JAVA and Android Studio.
1. ESP32 Device Side
1.1 System Framework
1.2 Hardware Description
The main control chip is the ESP32-WROVER-E, a general-purpose Wi-Fi + Bluetooth + Bluetooth LE MCU module. It is powerful and versatile, suitable for low-power sensor networks and demanding tasks such as voice encoding, audio streaming, and MP3 decoding. The ESP32-WROVER-E-N8R8 has 8MB of SRAM and 8MB of Flash, sufficient for voice recognition.
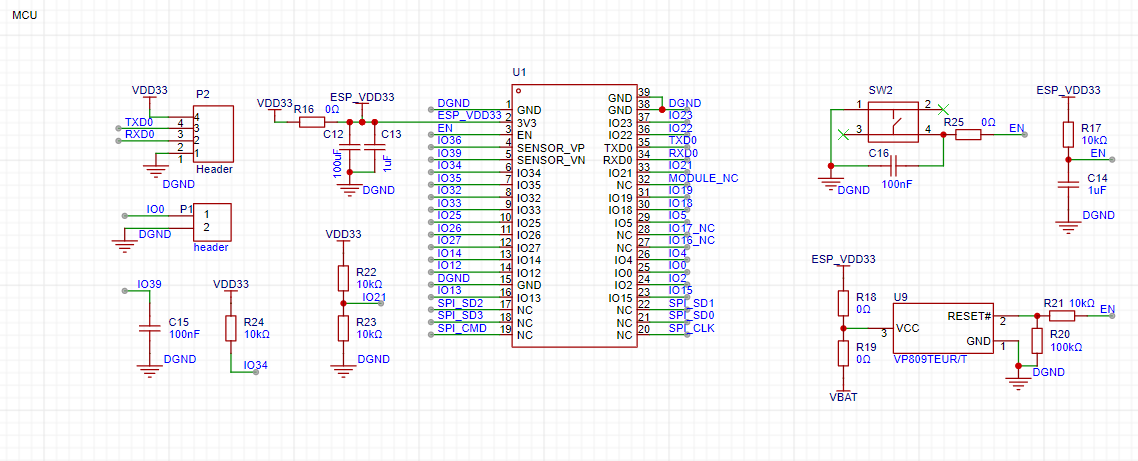
For power supply, it can be powered by USB or battery, with AP5056 for battery charging and discharging management. Two voltage regulators are used to power the ESP32 and audio chip respectively. The audio codec chip used
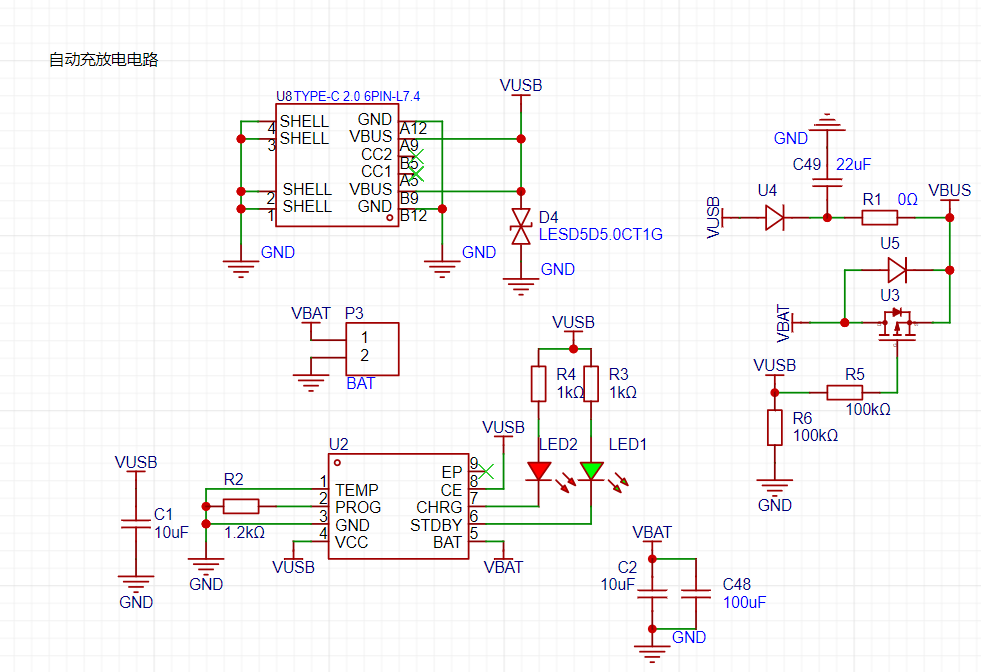
in the power supply circuit
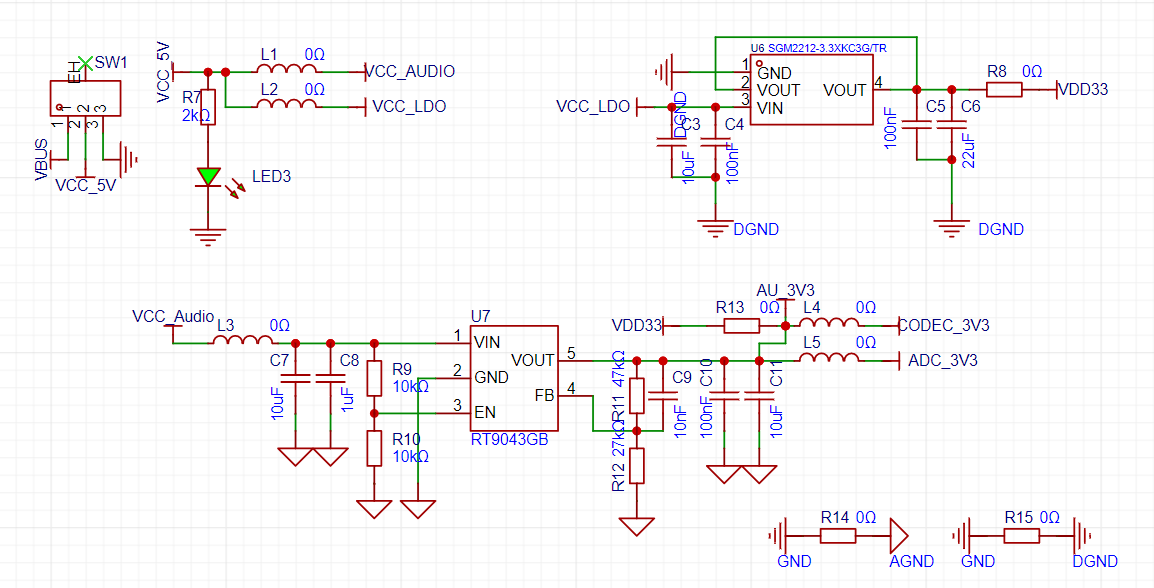
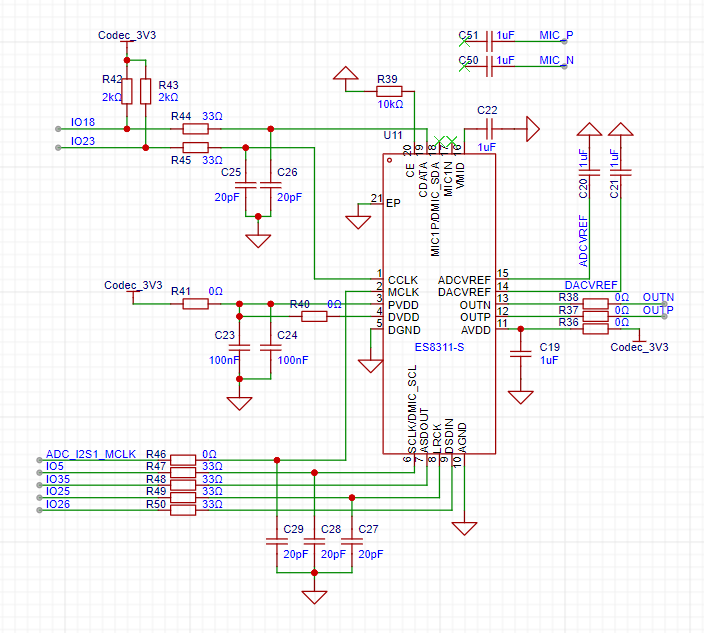
is the ES8311. The ES8311 is a widely promoted CODEC chip from Shunxin, offering high cost-effectiveness. Its main applications include portable audio devices, network cameras, and wireless audio. The ES8311 supports I2S communication with I2C-free configuration (MCLK/BCLK=64Fs), supports full-range input of ±1Vrms, and has low power consumption.
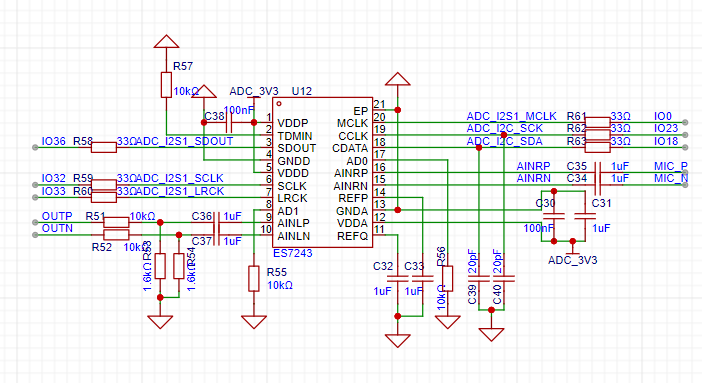
The ES7243E ADC chip is used to transmit the signal from the microphone to the ESP32. The ES7243E is a high-performance, advanced multi-bit Delta-sigma audio ADC chip widely promoted by Shunxin, featuring distortion up to -90dB THD+N, 24-bit, 8~48 kHz sampling rate, and automatic level control (ALC) and noise gate, offering excellent cost-effectiveness.
The audio amplification section uses the NS4150B chip. The NS4150B is an ultra-low EMI, filterless 3W mono Class D audio power amplifier. The NS4150B employs advanced technology to significantly reduce EMI interference across the entire bandwidth, minimizing its impact on other components. The NS4150B features built-in overcurrent, overheat, and undervoltage protection, effectively protecting the chip from damage under abnormal operating conditions. Furthermore, it utilizes spread spectrum technology to fully optimize the new circuit design, achieving an efficiency of up to 90%, making it ideal for portable audio products. The NS4150B's filterless PWM modulation structure and built-in gain reduce external components, PCB area, and system cost.
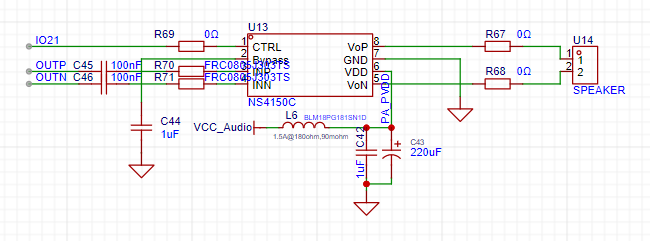
The PCB uses a double-layer design, with copper plating on the top for GND, DGND, and AGND respectively.
1.3 Code Flowchart
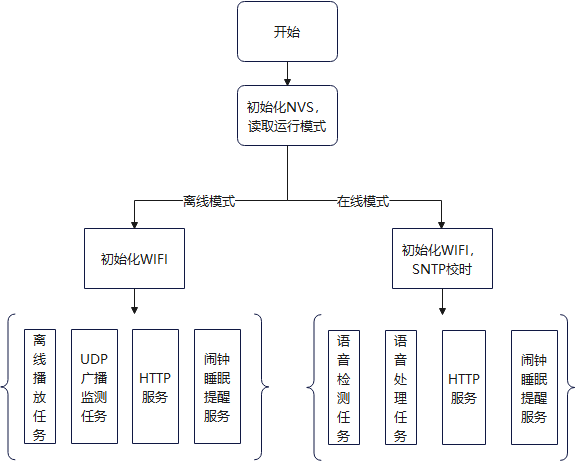
1.4 Software Code Description
On the hardware side, the performance of the ESP32 is fully utilized. Wake-up word detection and voice activity detection are implemented using the ESP32; only speech recognition and text-to-speech are implemented using the Baidu API.
1.4.1 Network Configuration Method
The Smartconfig component provided by the ESP-IDF can transmit the AP's SSID and password in promiscuous mode, and then use the obtained SSID and password to connect to the AP. Because the device uses the 2.4GHz Wi-Fi band, the mobile phone cannot connect to the router on the 5GHz band during network configuration; otherwise, the device will not receive data.
1.4.2 Online Music Playback
ESP-ADF develops audio applications by combining elements into a pipeline.
The audio pipeline used in this part of the program is as follows:
[http_server] ---> http_stream ---> mp3_decoder ---> i2s_stream ---> [codec_chip] The music URL is obtained from NetEase Cloud Music and played.
1.4.3 Voice Wake-up and VAD
The audio stream for voice wake-up and VAD is as follows: mic ---> codec_chip ---> i2s_driver ---> After the AFE detects the voice wake-up word, it activates VAD. If a human voice is detected, the data collected by the microphone is stored in the buffer.
1.4.4 Online Voice Interaction
In this section, data in the buffer is uploaded to Baidu Speech Recognition to obtain speech information, which is then uploaded to Baidu Qianfan to obtain the dialogue text returned by Wenxin Yiyan. This text is then converted into an HTTP audio stream for playback using Baidu TTS.
1.4.5 Offline Mode
The audio stream in offline mode is as follows:
[sdcard] ---> fatfs_stream ---> mp3_decoder ---> resample ---> i2s_stream ---> [codec_chip]
In offline mode, the ESP32's Wi-Fi operates in AP mode and is based on FreeRTOS. The ESP32 primarily runs three tasks:
First, audio playback. It initializes and reads audio files from the SD card and allows control of playback status and volume via external buttons.
Second, the ESP32 continuously listens for specific information on a specific port and responds, enabling its IP address to be recognized by smartphones connected to the network.
Third, the ESP32 acts as an HTTP server, receiving and processing POST requests containing control information sent by smartphones, thus enabling local control of the device.
1.4.6 Sleep Reminder and Alarm Reminder
After the set reminder time arrives and the corresponding reminder switch is turned on, the device can issue two reminders: "Time's up" or "Time to sleep."
2. Mobile App
2.1 Software Block Diagram
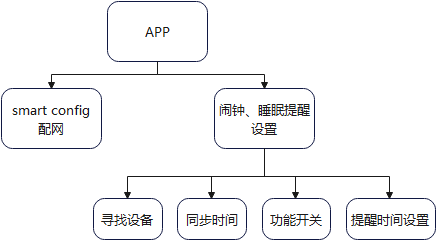
2.2 Software Functions
2.2.1 Network Configuration
The network configuration code refers to the open-source code of EspressifApp / EsptouchForAndroid and modifies it accordingly.
2.2.2 Alarm and Sleep Reminder Settings
Device detection uses a LAN UDP broadcast method. By sending specific data to the broadcast address of the subnet and listening to the received data, the IP address of the target device is identified and obtained. This method does not require group management, which greatly simplifies complexity, but may increase the burden on LAN bandwidth.
Time Synchronization The timestamp of the Android phone is obtained and sent to the ESP32 device to achieve time synchronization on the device side.
In addition, since the ESP32 device enables multiple HTTP server functions, sending corresponding data and requests to different HTTP interfaces using POST or GET methods can achieve the setting of different functions and the reading of the current status.
3. Cloud
3.1 Baidu Speech Recognition API Call
There are two POST methods for uploading voice data:
JSON format POST upload of local audio files and
RAW format POST upload of local audio files.
Since the first method requires base64 encoding of the collected audio data, increasing code complexity and data transmission volume, the second method is used here. The data collected by the microphone is directly uploaded to Baidu Cloud for recognition. The voice data is directly placed in the HTTP BODY, and control parameters and related statistical information are passed through parameters in the header and URL.
The following is an introduction to the parameters for uploading local audio files in RAW format POST.
Header Parameter Description
Field Name
Data Type
Required
Description
format
string (see example below)
Required
Voice format, pcm/wav/amr/ (m4a is only supported in the express version). Case insensitive. It is recommended to use the pcm file.
`rate
int` (see example below for format)
is required.
The sampling rate is 16000 or 8000, a fixed value.
The sampling rate and compression format of the audio data are indicated in the Content-Type of the HTTP-HEADER, e.g.,
Content-Type: audio/pcm;rate=16000
. `url` parameter description:
Field name ( optional, description
required ). `cuid` is required. It is a unique user identifier used to distinguish users and calculate UV values. It is recommended to fill in a machine MAC address or IMEI code that can distinguish users, with a length of no more than 60 characters. `token` is required . It is the developer's [access_token] obtained from the open platform. ` dev_pid` is optional . If not filled in, the lan parameter takes effect. If not filled in, the default is 1537 (Mandarin input method model). The `dev_pid` parameter is shown in the table at the beginning of this section. `lm_id int` is optional . `lan` is optional. This is a deprecated historical compatible parameter and is no longer used. Detailed reference documentation: Short Speech Recognition API 3.2 Wenxin Yiyan API Call. Baidu Smart Cloud Qianfan Large Model Platform is a one-stop enterprise-level large model platform, providing an advanced generative AI production and application full-process development toolchain. Currently, Baidu Smart Cloud Qianfan Large Model Platform is officially open to enterprises and individuals, allowing them to apply for and use the Wenxin Yiyan large language model on this platform. After receiving the speech-text returned by Baidu Cloud's speech recognition service, we use a POST request to call the Wenxin Yiyan API to send the recognized text to Wenxin Yiyan and receive a corresponding response, thus achieving intelligent interaction. An example of the request's JSON data is as follows: { "messages": [ { "role": "user", "content": "Introduce yourself" } ] } It supports single-turn, multi-turn, and streaming requests. Detailed documentation is as follows: Reference Documentation: Wenxin Yiyan API 3.3 NetEase Cloud Music API Service Setup. This part requires your own server or you can use a personal computer to set up a service. It requires Node.js. See the documentation below for details.
Reference Document: NetEase Cloud Music API Server Setup Reference Manual
3.4 Server-Side API Service Setup
On the server side, Flask is used to build the API to handle device requests, parse the text recognized by the device, and divide it into "play music" and "voice interaction" commands, and execute the corresponding operations, returning the audio stream played by the device. Specific code is shown in the attached server.py file.
4. Shell Design
The shell was designed using Fusion360. This software provides excellent version management, facilitating model modification and rollback, and offers a free educational version for university students. Although it is somewhat similar to Inventor, I personally feel it is not as user-friendly as Inventor, perhaps because I am more accustomed to using Inventor.

3D model printing was done using LCSC's 3D Monkey, which produces a finer print quality than my own 3D printer and is cheaper.
A simple panel was also designed in this project as follows:
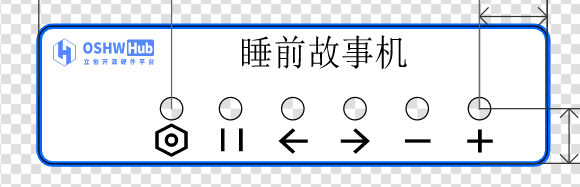
The ability to design and print panels directly in LCSC EDA is very convenient and user-friendly.
5. Physical Demonstration


6. App Interface
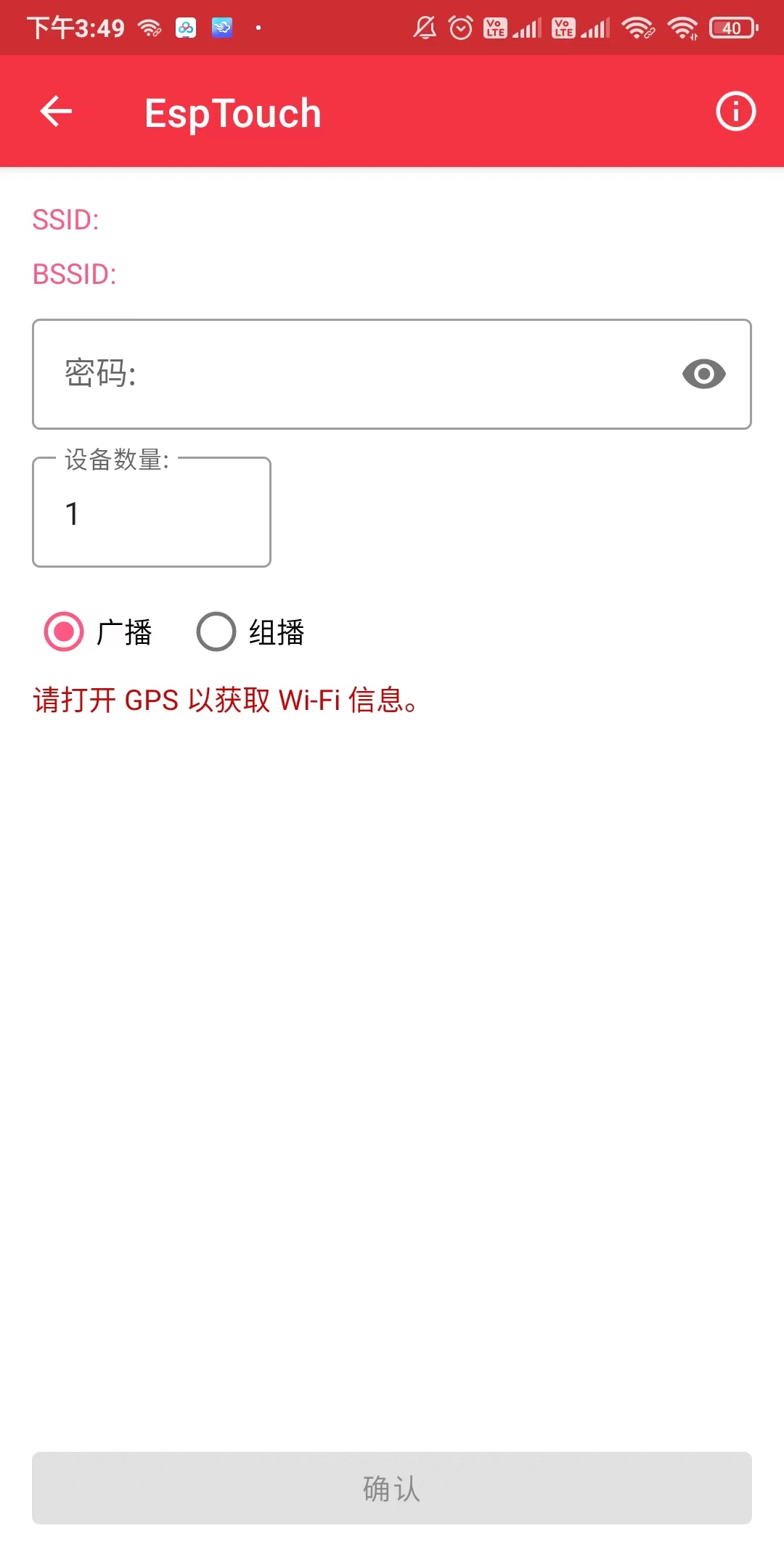
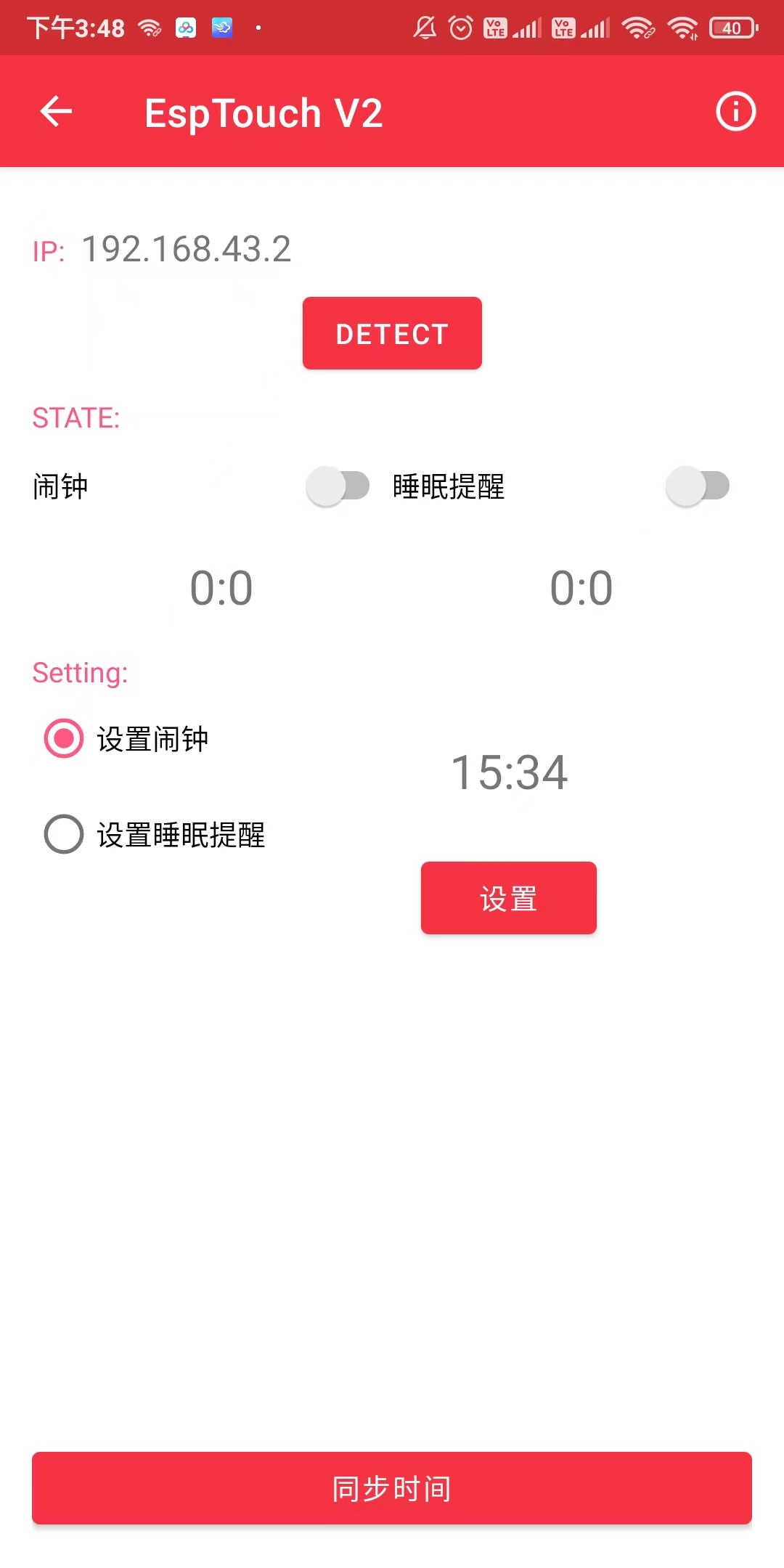
Design Considerations
IDF can use the built-in esp-adf IDF, version 4.4. Higher versions may encounter inexplicable errors when using voice wake-up and VAD.
The board does not have a USB-to-serial chip; an external CH340 module is required for program download and debugging.
Wenxin Yiyan requires ERNIE-Bot, not ERNIE-Bot-turbo, otherwise the timeliness of the returned data cannot be guaranteed.
When calling the Baidu Wenxin Yiyan and speech recognition APIs, the corresponding tokens must be obtained first; the tokens for the two API interfaces are different.
Due to the large number of resources used by the program, remember to use WROVER (with SRAM, do not buy WROOM!!!), and enable external RAM in menuconfig.
Local playback only supports MP3 audio format.
SD card directory structure:
sdcard
|---play
| |--a.mp3
| |--b.mp3
|---alarm
| |--0.mp3
|
Problems and Solutions Encountered (--1.mp3):
I tried both the TTS library built into the ESP32 and the zhtts library in Python. While these met basic requirements, their voice quality was poor, and their performance with long texts was subpar. Therefore, I switched to the Baidu TTS solution.
Note that the ADC chip is ES7243, not ES7243E. If the wrong chip was purchased, it needs to be changed from ES7243 to ES7243E. The specific files to modify are bord.c and bord_def.h.
Because the music returned by the NetEase Cloud Music interface is stereo and has a high bitrate, it causes playback stuttering and the device cannot be voice-activated after playback. Therefore, I wrote a simple program on the server side to convert the music returned by the interface into mono with a bitrate of 16000 before sending it to the device.
Other:
This is my first open-source project. I am very grateful to JLCPCB for providing this platform, giving me this opportunity to improve myself. This document was written in a bit of a rush, and there may be many unclear or inappropriate points. Please feel free to criticize and correct me! We can also exchange ideas and learn together if you have any questions!
Since the ESP touch cannot transmit the password for the phone's own hotspot, if you only have one phone and there is no available Wi-Fi nearby, you need to first create a Wi-Fi network with the same SSID and password using a computer, and then connect the phone to this network before performing smart configuration. Finally, turn off the computer hotspot, turn on the phone hotspot, reset the hardware, and then connect it to the phone hotspot
board. The board was hand-soldered, and the package mainly uses 0805, which makes the board size slightly larger. In the future, smaller packages and JLCPCB SMT surface mount technology can be used. The ES8311 and ES7243 are QFN packages, and this is the first time I have soldered QFN packaged chips (I initially tried to solder with a soldering iron, which resulted in the failure of two boards). I recommend using a hot air gun. I used low-temperature lead-free solder and a small DIY hot air gun.
You can modify other built-in wake words in menuconfig. This project uses "Hello, Xiaozhi".
You can use the lyrat-mini Hal library for code development.
There may be issues with the app. The DETECT button needs to be pressed twice to accurately recognize the device, and if the parameters are set too quickly, there is a chance of crashing.
Some components are redundant and do not require soldering, specifically:
R13 R17 R19 R20 R22
C9 C50 C51 D1 D2 D3.
Demo video:
Bedtime Story Machine Function Demonstration: https://www.bilibili.com/video/BV18e41197Lv/
Project code has been uploaded to GitHub, links are as follows:
https://github.com/fengzhaoxin/storytellerAPP.git
https://github.com/fengzhaoxin/storyteller.git








 京公网安备 11010802033920号
京公网安备 11010802033920号

 M5-512/256-12HI
M5-512/256-12HI